Правильное управление поведением поисковых роботов является важной частью SEO-стратегии любого ресурса. Для эффективного взаимодействия с ними используется специальный инструмент — файл robots.txt, который служит инструкцией для ботов поисковых систем относительно того, как именно обрабатывать ваш ресурс.
От SEO-специалистов часто можно услышать такие фразы, как «нужен запрет индексации сайта через robots txt» или «сайт нужно закрыть от индексации». В этой статье мы расскажем о том, что такое файл robots.txt, в чем разница между индексацией и сканированием и как настроить запрет индексации папки, страницы и сайта.
Чтобы убрать весь сайт или отдельные его разделы и страницы из поисковой выдачи Google, Яндекс и других поисковых систем, их нужно закрыть от индексации. Тогда контент не будет отображаться в результатах поиска. Рассмотрим, с помощью каких команд в файле robots.txt можно ограничить сканирование страниц и тем самым повлиять на их индексацию.
Не индексировать сайт: для чего это нужно
Первое время после публикации сайта о нем знает только ограниченное число пользователей. Например, разработчики или клиенты, которым компания прислала ссылку на свой веб-ресурс. Чтобы сайт посещало больше людей, его страницы должны быть обнаружены и добавлены в индекс поисковых систем. Для этого поисковые системы используют специальные программы — поисковых роботов, которые анализируют содержимое веб-страниц. Этот процесс называется сканированием.
После того как пройдет первое успешное сканирование, алгоритмы поисковых систем принимают решение о включении страниц в индекс, и только затем страницы сайта начинают отображаться в поисковой выдаче, то есть индексироваться. Пользователи видят их в результате поиска в Яндекс и Google — двух крупнейших поисковых системах, работающих в России. Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, содержащие соответствующую информацию.
Однако не все страницы сайта должны попадать в поисковую выдачу. Есть контент, который интересен пользователям: статьи, страницы услуг, товары. А есть служебная информация: временные файлы, документация к ПО и т. п. Когда полезные материалы находятся рядом с техническими или устаревшими элементами, это усложняет поиск нужной информации пользователями и снижает качество поискового опыта. Поэтому такие страницы рекомендуется закрывать от индексации, а при необходимости — ограничивать их сканирование.
Кроме отдельных страниц и разделов, веб-разработчикам иногда требуется убрать весь ресурс из поисковой выдачи. Например, если на нем идут технические работы или вносятся глобальные правки по дизайну и структуре. Если сайт не закрыт для индексации, часть страниц может показываться в поисковой выдаче до завершения изменений, что иногда приводит к некорректному отображению результатов.
Чем сканирование отличается от индексации
Важно понимать разницу между этими двумя понятиями:
— сканирование — это процесс, при котором робот посещает вашу страницу и собирает информацию о содержимом. То есть «читает» контент вашей страницы;
— индексация — это уже результат сканирования. После успешного сканирования информация сохраняется в базах данных поисковых систем и становится доступной пользователям при поиске. Страницы могут быть просканированы, но не обязательно попадут в индекс.
Файл robots.txt непосредственно регулирует лишь процесс сканирования, давая инструкции роботу, какие страницы и ресурсы разрешено посещать, а какие — нет. Однако сам факт запрета сканирования в robots.txt не гарантирует немедленного исключения страницы из результатов поиска. Даже если робот перестанет посещать страницу, ранее проиндексированная страница может оставаться в выдаче некоторое время.
Чтобы окончательно исключить страницу из индекса, нужно применять дополнительный метод — использование метатега meta name=«robots» content=«noindex». Этот тег прямо дает возможность закрыть страницу от индексации даже в случаях, когда робот всё еще имеет право ее сканировать согласно файлу robots.txt.
Таким образом, важно помнить:
— файл robots.txt контролирует процесс сканирования.
— метатег meta управляет процессом индексации.
Правильное сочетание обоих методов позволит эффективно управлять видимостью ваших страниц в результатах поиска.
Далее рассмотрим, как правильно сообщать роботам о запрете посещения и сканирования страниц сайта. Директива, отвечающая за это действие, называется Disallow.
Как запретить сканирование сайта
О том, где найти файл robots.txt, как его создать и редактировать, мы подробно рассказали в статье. Если кратко — файл можно найти в корневой папке. А если он отсутствует, сохранить на компьютере пустой текстовый файл под названием robots.txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
Чтобы запретить сканирование всего всего сайта:
-
1
Откройте файл robots.txt.
-
2
Добавьте в начало нужные строки.
- Чтобы закрыть сайт во всех поисковых системах (действует для всех поисковых роботов):
User-agent: * Disallow: /- Для запрета сканирования только одной системой (например, в Яндекс)
User-agent: YandexBot Disallow: /- Запретить все поисковики, кроме одного (например, Google)
User-agent: Googlebot Allow: / User-agent: * Disallow: / -
3
Сохраните изменения в robots.txt.
Готово. С этого момента поисковые роботы не смогут сканировать сайт. Однако это не гарантирует немедленного удаления страниц из индекса. Для полного удаления страниц из выдачи может потребоваться дополнительное использование метатега noindex или инструментов вебмастера.
Запрет сканирования каталога
Гораздо чаще, чем закрывать от индексации весь веб-ресурс, разработчикам требуется скрывать отдельные папки и разделы.
Чтобы запретить поисковым роботам просматривать конкретный раздел:
-
1
Откройте robots.txt.
-
2
Укажите поисковых роботов, на которых будет распространяться правило. Например:
- Все поисковые системы:
User-agent: *— Запрет только для Яндекса:
User-agent: YandexBot -
3
Задайте правило Disallow с названием папки/раздела, который хотите запретить:
Disallow: /catalog/Где вместо catalog — укажите нужную папку.
-
4
Сохраните изменения.
Готово. Теперь указанный каталог скрыт от сканирования поисковыми системами. Аналогичным способом можно задать запрет на несколько папок подряд, добавив дополнительные строчки Disallow. Если его страницы уже были проиндексированы, для их удаления из выдачи потребуется дополнительно использовать метатег noindex.
Как закрыть служебную папку wp-admin в плагине Yoast SEO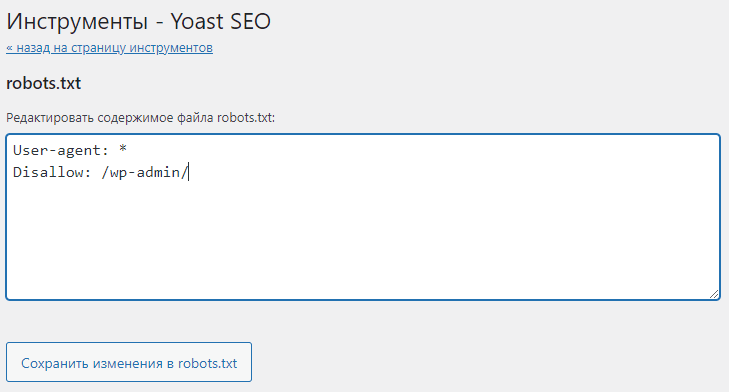
Закрытие страницы от сканирования в robots.txt
Если нужно закрыть от сканирования конкретную страницу (например, с устаревшими акциями или неактуальными контактами компании):
-
1
Откройте файл robots.txt на хостинге или используйте плагин Yoast SEO, если сайт на WordPress.
-
2
Укажите, для каких поисковых роботов действует правило.
-
3
Задайте директиву Disallow и относительную ссылку (то есть адрес страницы без домена и префиксов) той страницы, которую нужно скрыть. Например:
User-agent: * Disallow: /catalog/page.htmlГде вместо catalog — введите название папки, в которой содержится файл, а вместо page.html — относительный адрес страницы.
-
4
Сохраните изменения.
Готово. Данная страница не будет доступна для сканирования поисковыми роботами.
Запрет сканирования не гарантирует автоматическое удаление из поисковой выдачи. Если необходимо быстро удалить уже существующие страницы из поиска, дополнительно установите на страницах метатег noindex.
Обратите внимание
Если страница одновременно закрыта в robots.txt и содержит метатег noindex, поисковый робот может не увидеть noindex, поскольку ему запрещено сканирование. Поэтому сначала следует установить noindex и дождаться удаления страницы из индекса, а уже затем при необходимости добавлять Disallow.
Как применить метатег noindex
Файл robots.txt позволяет предотвратить сканирование страниц, однако страницы, уже попавшие в индекс, останутся видимыми в результатах поиска. Чтобы удалить такую страницу из поисковой выдачи, добавьте на нее метатег .
Этот метатег записывается следующим образом:
<head>
<meta name="robots" content="noindex">
</head>Эта команда запрещает поисковому роботу включать данную страницу в индекс при условии, что она доступна для сканирования.
Для установки метатега вручную перейдите в HTML-код интересующей вас страницы и найдите секцию head. Внутри секции вставьте следующую строку:
<meta name="robots" content="noindex">Сохраните изменения.
Теперь страница будет закрыта от индексации и вскоре исчезнет из поисковой выдачи.
Используя приведенные рекомендации, вы сможете эффективно управлять индексацией сайта и отображением страниц в поисковой выдаче.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊