Рассмотрим, зачем нужен файл robots.txt для WordPress, где он находится на хостинге и как настроить правильный robots.txt для WordPress.
Для чего нужен файл robots.txt?
Для того чтобы сайт начал отображаться в Яндекс, Google, Yahoo и других поисковых системах (ПС), они должны внести его страницы в свои каталоги. Этот процесс называется индексацией.
Чтобы проиндексировать тот или иной веб-ресурс, поисковые системы посылают на сайты поисковых роботов (иногда их называют ботами). Они методично сканируют и обрабатывают содержимое каждой страницы сайта. После окончания индексации начинается «социальная жизнь» ресурса: его контент попадается пользователям в результатах поиска по запросам.
Многие сайты создаются на готовых движках и CMS (системах управления контентом) WordPress, Joomla, Drupal и других. Как правило, такие системы содержат страницы, которые не должны попадать в поисковую выдачу:
- временные файлы (tmp);
- личные данные посетителей (private);
- служебные страницы (admin);
- результаты поиска по сайту и т. д.
Чтобы внутренняя информация не попала в результаты поиска, ее нужно закрыть от индексации. В этом помогает файл robots.txt. Он служит для того, чтобы сообщить поисковым роботам, какие страницы сайта нужно индексировать, а какие — нет. Иными словами, robots.txt — это файл, состоящий из текстовых команд (правил), которыми поисковые роботы руководствуются при индексации сайта.
Наличие robots.txt значительно ускоряет процесс индексации. Благодаря нему в поисковую выдачу не попадают лишние страницы, а нужные индексируются быстрее.
Где находится robots.txt WordPress?
Файл robots.txt находится в корневой папке сайта. Если сайт создавался на WordPress, скорее всего, robots.txt присутствует в нем по умолчанию. Чтобы найти robots.txt на WordPress, введите в адресной строке браузера:
https://www.домен-вашего-сайта/robots.txt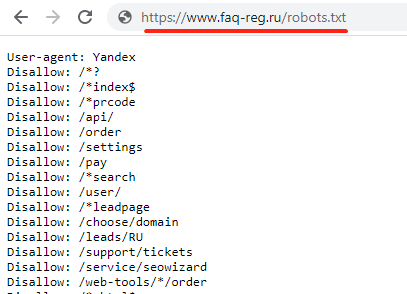
- Если файл присутствует, откроется страница с перечнем правил индексации. Однако чтобы редактировать их, вам потребуется найти и открыть robots.txt на хостинге. Как правило, он находится в корневой папке сайта:
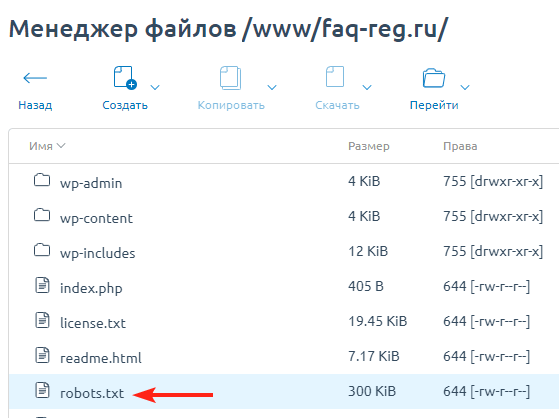
- Если же файл robots.txt по какой-то причине отсутствует, вы можете создать его вручную на своем компьютере и загрузить на хостинг или воспользоваться готовыми решениями (плагинами WordPress).
Как создать файл robots.txt для WordPress?
Есть два способа создания robots.txt:
-
1.
Вручную на компьютере.
-
2.
С помощью плагинов в WordPress.
Первый способ прост лишь на первый взгляд. После создания пустого документа и загрузки его на сайт, вы должны будете наполнить его содержанием (директивами). Ниже мы расскажем об основных правилах, однако стоит учитывать, что тонкая настройка требует специальных знаний SEO-оптимизации.
Создание robots.txt вручную
-
1
Откройте программу «Блокнот».
-
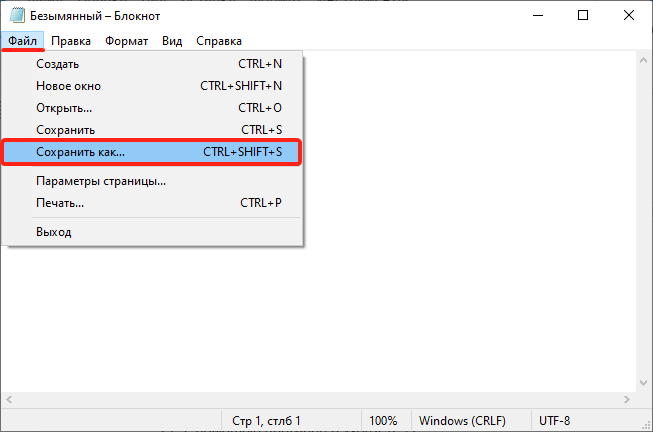
2
Нажмите Файл → Сохранить как… (или комбинацию клавиш Ctrl + Shift + S):
-
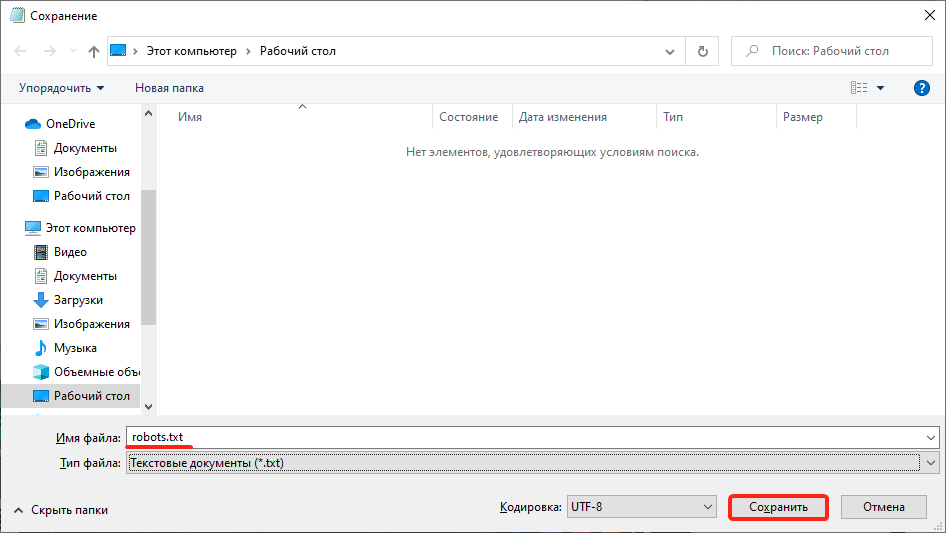
3
Введите название robots.txt и нажмите Сохранить.
-
4
Откройте корневую папку сайта и загрузите в нее созданный файл по инструкции.
Готово, вы разместили пустой файл и после этого сможете редактировать его прямо в панели управления хостингом.
Создание robots.txt с помощью плагина
-
1
Откройте административную панель WordPress по инструкции.
-
2
Перейдите в раздел «Плагины» и нажмите Добавить новый:
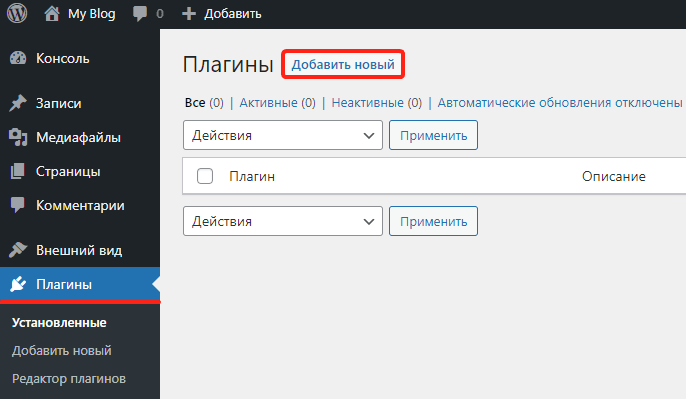
-
3
Введите в строке поиска справа название Yoast SEO и нажмите Enter.
-
4
Нажмите Установить → Активировать:
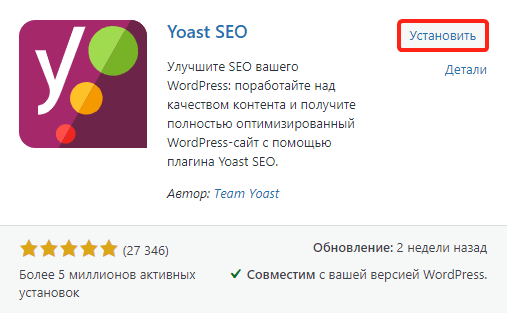
-
5
Перейдите к настройкам плагина, выбрав в меню SEO → Инструменты. Затем нажмите Редактор файлов:

-
6
Нажмите Создать файл robots.txt:
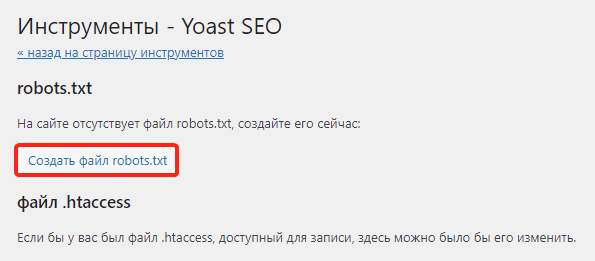
-
7
Нажмите Сохранить изменения в robots.txt:
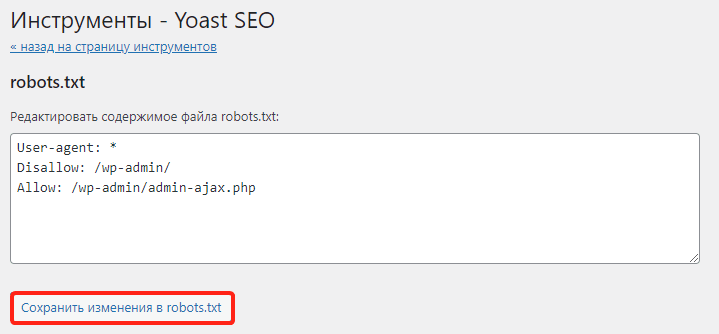
Готово, файл с минимальным количеством директив будет создан автоматически.
Настройка robots.txt WordPress
После создания файла вам предстоит настроить robots.txt для своего сайта. Рассмотрим основы синтаксиса (структуры) этого файла:
- Файл может состоять из одной и более групп директив (правил).
- В каждой группе должно указываться, для какого поискового робота предназначены правила, к каким разделам/файлам у него нет доступа, а к какому — есть.
- Правила читаются поисковыми роботами по порядку, сверху вниз.
- Файл чувствителен к регистру, поэтому если название раздела или файла задано капслоком (например, FILE.PDF), именно так стоит писать и в robots.txt.
- Все правила одной группы должны следовать без пропуска строк.
- Чтобы оставить комментарий, нужно прописать шарп (#) в начале строки.
Все правила в файле задаются через двоеточие. Например:
User-agent: GooglebotГде User-agent — команда (директива), а Googlebot — значение.
Основные директивы и их значения
User-agent — эта директива указывает, на каких поисковых роботов распространяются остальные правила в документе. Она может принимать следующие значения:
- User-agent: * — общее правило для всех поисковых систем;
- User-agent: Googlebot — робот Google;
- User-agent: Yandex — робот Яндекс;
- User-agent: Mai.ru — робот Mail.ru;
- User-agent: Yahoo Slurp — робот Yahoo и др.
У крупнейших поисковых систем Яндекс и Google есть десятки роботов, предназначенных для индексации конкретных разделов и элементов сайтов. Например:
- YandexBot — для органической выдачи;
- YandexDirect — для контекстной рекламы;
- YandexNews — для новостных сайтов и т. п.
Для решения некоторых специфических задач веб-разработчики могут обращаться к конкретным поисковым роботам и настраивать правила исключительно для них.
Disallow — это директива, которая указывает, какие разделы или страницы нельзя посещать поисковым роботам. Все значения задаются в виде относительных ссылок (то есть без указания домена). Основные правила запрета:
- Disallow: /wp-admin — закрывает админку сайта;
- Disallow: /cgi-bin — запрет индексации директории, в которой хранятся CGI-скрипты;
- Disallow: /*? или Disallow: /search — закрывает от индексации поиск на сайте;
- Disallow: *utm* — закрывает все страницы с UTM-метками;
- Disallow: */xmlrpc.php — закрывает файл с API WordPress и т. д.
Вариантов того, какие файлы нужно закрывать от индексации, очень много. Вносите значения аккуратно, чтобы по ошибке не указать контентные страницы, что повредит поисковой позиции сайта.
Allow — это директива, которая указывает, какие разделы и страницы должны проиндексировать поисковые роботы. Как и с директивой Disallow, в значении нужно указывать относительные ссылки:
- Allow: /*.css или Allow: *.css — индексировать все css-файлы;
- Allow: /*.js — обходить js-файлы;
- Allow: /wp-admin/admin-ajax.php — разрешает индексацию асинхронных JS-скриптов, которые используются в некоторых темах.
В директиве Allow не нужно указывать все разделы и файлы сайта. Проиндексируется всё, что не было запрещено директивой Disallow. Поэтому задавайте только исключения из правила Disallow.
Sitemap — это необязательная директива, которая указывает, где находится карта сайта Sitemap. Единственная директива, которая поддерживает абсолютные ссылки (то есть местоположение файла должно указываться целиком): Sitemap: https://site.ru/sitemap.xml , где site.ru — имя домена.
Также есть некоторые директивы, которые считаются уже устаревшими. Их можно удалить из кода, чтобы не «засорять» файл:
- Crawl-delay. Задает паузу в индексации для поисковых роботов. Например, если задать для Crawl-Delay параметр 2 секунды, то каждый новый раздел/файл будет индексироваться через 2 секунды после предыдущего. Это правило раньше указывали, чтобы не создавать дополнительную нагрузку на хостинг. Но сейчас мощности современных процессоров достаточно для любой нагрузки.
- Host. Указывает основное зеркало сайта. Например, если все страницы сайта доступны с www и без этого префикса, один из вариантов будет считаться зеркалом. Главное — чтобы на них совпадал контент. Раньше зеркало нужно было задавать в robots.txt, но сейчас поисковые системы определяют этот параметр автоматически.
- Clean-param. Директива, которая использовалась, чтобы ограничить индексацию совпадающего динамического контента. Считается неэффективной.
Пример robots.txt
Рассмотрим стандартный файл robots.txt, который можно скопировать и использовать для блога, заменив название домена в директиве Sitemap и убрав комментарии (текст справа, включая #):
User-agent: * # общие правила для всех поисковых роботов
Disallow: /wp-admin/ # запретить индексацию папки wp-admin (все служебные папки)
Disallow: /readme.html # закрыть доступ к стандартному файлу о программном обеспечении
Disallow: /*? # запретить индексацию результатов поиска по сайту
Disallow: /?s= # запретить все URL поиска по сайту
Allow: /wp-admin/admin-ajax.php # индексировать асинхронные JS-файлы темы
Allow: /*.css # индексировать CSS-файлы
Allow: /*.js # индексировать JS-скрипты
Sitemap: https://site.ru/sitemap.xml # указать местоположение карты сайтаКак редактировать robots.txt на WordPress?
Чтобы внести изменения в файл robots.txt, откройте его в панели управления хостингом. Используйте плагин Yoast SEO (или аналогичное решение в WordPress) для редактирования файлов:
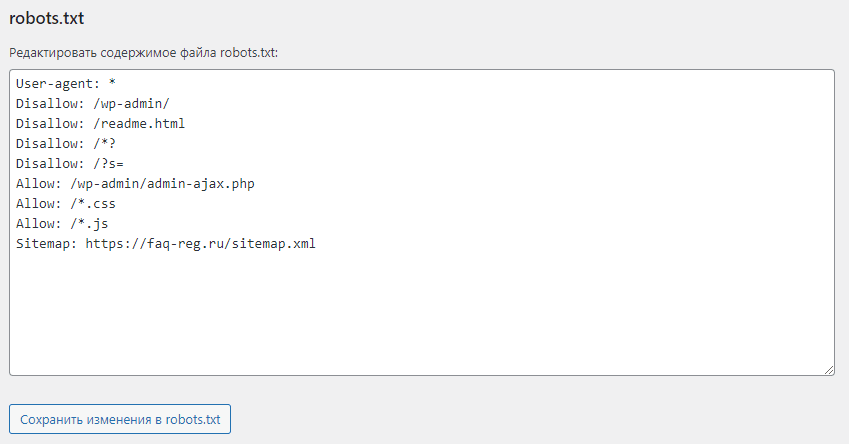
Проверка работы файла robots.txt
Чтобы убедиться в корректности составленного файла, используйте стандартный инструмент Яндекс.Вебмастер:
-
1
Откройте страницу.
-
2
Перейдите в раздел Инструменты → Анализ robots.txt.
-
3
Содержимое robots.txt обновится автоматически. Нажмите Проверить:
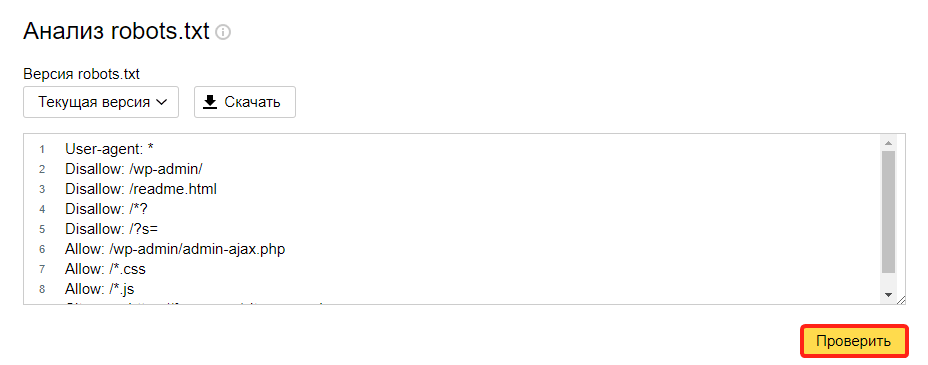
Если в синтаксисе файла будут ошибки, Яндекс укажет, в каких строчках проблема и даст рекомендации по исправлению.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊