Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
-
1.
Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
-
2.
Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
-
3.
Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
-
4.
Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов
Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями
Disallow: /*? # запрет индексации результатов поиска на сайте
Allow: /wp-admin/admin-ajax.php # разрешение индексации JS-скрипты темы WordPress
Allow: /*.jpg # разрешение индексации всех файлов формата .jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайтаСоветы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
# пустая строка
User-agent: Googlebot # правила только для ПС Google
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
Sitemap: # адрес файлаУчитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots.txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/
Disallow: /authors/
Disallow: /css/Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
-
1
Зайдите в личный кабинет Яндекс.Вебмастер.
-
2
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
-
3
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:

проверка robotstxt 1
-
4
Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:

Google Search Console
Чтобы сделать проверку с помощью Google:
-
1
Перейдите на страницу инструмента проверки.
-
2
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
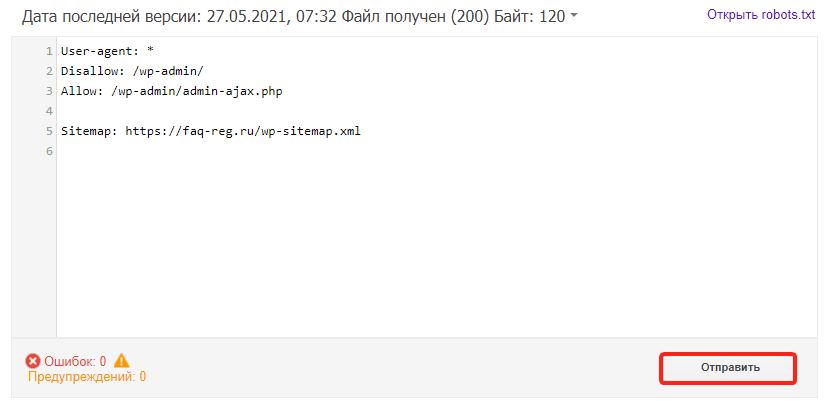
-
3
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.

Проверка robots.txt Google не выявила ошибок
Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots.txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊