В статье мы расскажем, что такое S3, а также о способах доступа к объектам в нем.
Что такое хранилище S3
Существуют несколько типов хранилищ. Выделим три основных:
-
1.
Файловая система — наиболее популярный тип хранилища S3. Чаще всего она используется при организации хранения файлов на ПК или мобильном устройстве.
-
2.
Блочное хранилище — способ хранения данных на физических носителях. Он имеет высокую производительность и используется при организации хранилища в СУБД или платформах виртуализации.
-
3.
Объектное хранилище (или хранилище S3) позволяет размещать данные большого объема в любом формате — они называются объектами. Именно об этом типе хранилища пойдет речь в статье.
S3 (Simple Storage Service) — это технология, которая используется для организации хранения данных. Она была разработана компанией Amazon Web Services (AWS) в 2006 году. Изначально S3 представляла собой API для доступа к объектам с помощью уникальных ссылок по протоколам HTTP или HTTPS. Однако со временем регулировка доступов к объектам хранилища стала более гибкой: можно выбрать публичный и приватный доступ в зависимости от нужд проекта.
Как работает хранение данных в S3
Хранение данных в S3 организовано таким образом, что внутри хранилища созданы специальные контейнеры (папки), в которых равномерно распределяются данные. Также их принято называть бакетами.
В каждом бакете, в свою очередь, размещены объекты — неструктурированные данные. Каждый из этих объектов содержит следующую информацию:
- идентификатор,
- метаданные.
Это позволяет работать не только с бакетом целиком, но и с отдельными объектами внутри: для этого достаточно «обратиться» к файлу по его идентификатору или воспользоваться поиском по метаданным.
Чтобы работа с S3-хранилищем была удобной, разработчики компании Amazon Web Services создали одноименное клиентское приложение. Оно называется aws cli и поддерживается большинством популярных операционных систем.
Преимущества и недостатки облачного S3-хранилища
Как любое облачное решение, S3 имеет свои сильные и слабые стороны. Начнем с преимуществ:
-
1.
Доступ к объектам через HTTP API. HTTP API — это функционал, который позволяет установить соединение между клиентом и сервером по протоколу HTTP. Этот протокол (как и его расширение HTTPS) используется для отображения веб-страниц в интернете. Благодаря этой особенности для работы с данными достаточно иметь стабильное интернет-соединение.
-
2.
Быстрый поиск объектов в бакетах. Поиск конкретных данных выполняется при помощи расширенных метаданных объекта и плоского адресного пространства — в нем все адреса представлены в виде непрерывного диапазона.
-
3.
Гибкое масштабирование. Облачное объектное хранилище поддерживает быстрое масштабирование. Это значит, что добавить дополнительные ресурсы можно в любой момент (например, на время повышенной нагрузки на ваш сайт).
-
4.
Поддержка многих типов данных. S3 позволяет хранить данные любого типа и размера. Так вы можете разместить текстовые документы, архивы, медиафайлы и многое другое.
-
5.
Встроенный механизм репликации. Обычно объектное хранилище размещается на распределенных серверах с поддержкой репликации. Это значит, что информация оперативно обновляется для всех пользователей.
Несмотря на весомые преимущества, объектное хранилище S3 имеет недостатки:
-
1.
Зависимость от интернет-соединения. Работать с объектами хранилища можно только при наличии стабильного интернета. Это может вызвать трудности при сбое соединения или в местах, где интернет работает с перебоями.
-
2.
Сложность управления. Технология S3 позволяет гибко настроить хранилище под нужды проекта, однако это требует специальных технических навыков. Из-за этого использование объектного хранилища может быть сложным для новичков.
Примеры использования облачных хранилищ
Облачные хранилища универсальны и подходят практически для любых задач. Что можно хранить в S3:
-
1.
Резервные копии. S3 позволяет хранить резервные копии — это поможет оперативно восстановить состояние проекта в случае аварии.
-
2.
Статический контент. В хранилище можно разместить изображения, аудио, видео, стили и другие неизменяющиеся файлы, чтобы ускорить загрузку сайта.
-
3.
Тестовую среду разработки. Технология S3 позволяет развернуть тестовую среду внутри хранилища. Это помогает ускорить разработку приложений.
-
4.
Файлы для обмена с другими пользователями. В рамках хранилища S3 можно создать пространство для обмена файлами. Такой файлообменник работает аналогично популярным сервисам (например, Яндекс Диск или Google Диск).
-
5.
CDN. CDN — это сеть доставки контента. Она представляет собой несколько объединенных серверов, которые размещены в разных регионах и доставляют контент для пользователей конкретного города или страны. Вы можете задействовать S3 для добавления к основному набору серверов или создать сеть, целиком состоящую из облачных хранилищ.
Способы доступа к файлам в хранилище S3
Существует несколько способов доступа к объектам хранилища:
-
1.
С аутентификацией — для подключения к бакету по ключам доступа.
-
2.
Без аутентификации — для бакетов с публичным типом доступа.
-
3.
По предподписанным ссылкам — если доступ требуется ограниченное время.
Настройку каждого из типов доступа мы покажем на примере утилиты aws cli — ее необходимо установить на ПК, с которого вы планируете подключаться. Инструкцию по установке aws cli можно найти в официальной документации.
Доступ с аутентификацией
Для настройки этого способа доступа необходимо создать конфигурацию с указанием ключей. Но сначала вам потребуются параметры доступа. Чтобы получить их:
-
1
Авторизуйтесь в личном кабинете.
-
2
Откройте панель управления облаком.
-
3
Перейдите в раздел Мои ресурсы — Хранилище S3 — Ключи доступа:
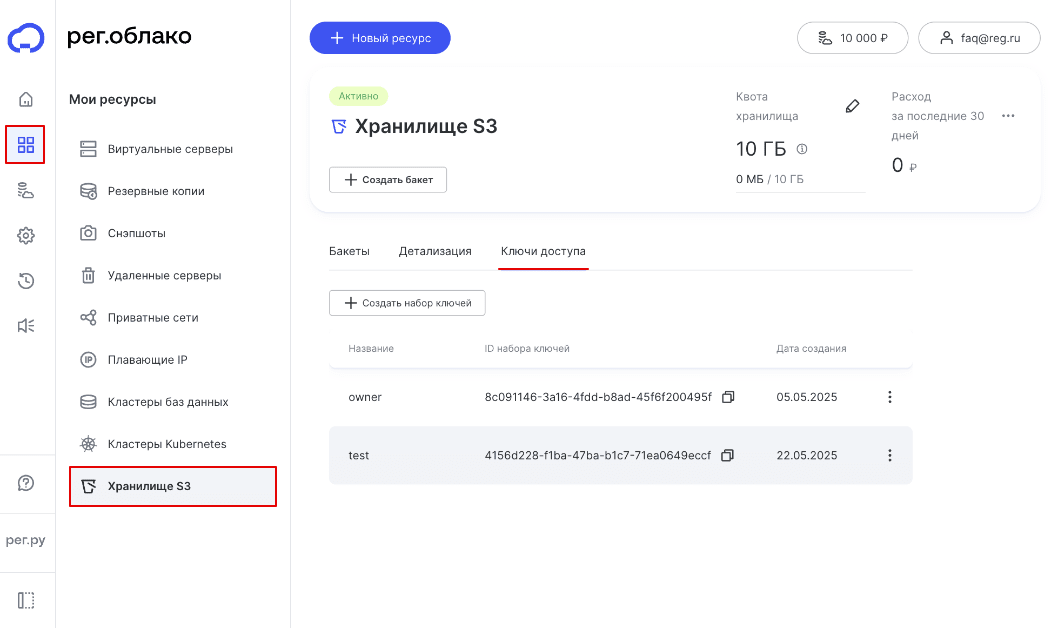
О том, сколько стоит S3, можно узнать при заказе услуги
-
4
В строке с набором ключей нажмите на три точки. В выпадающем списке выберите Параметры набора ключей:
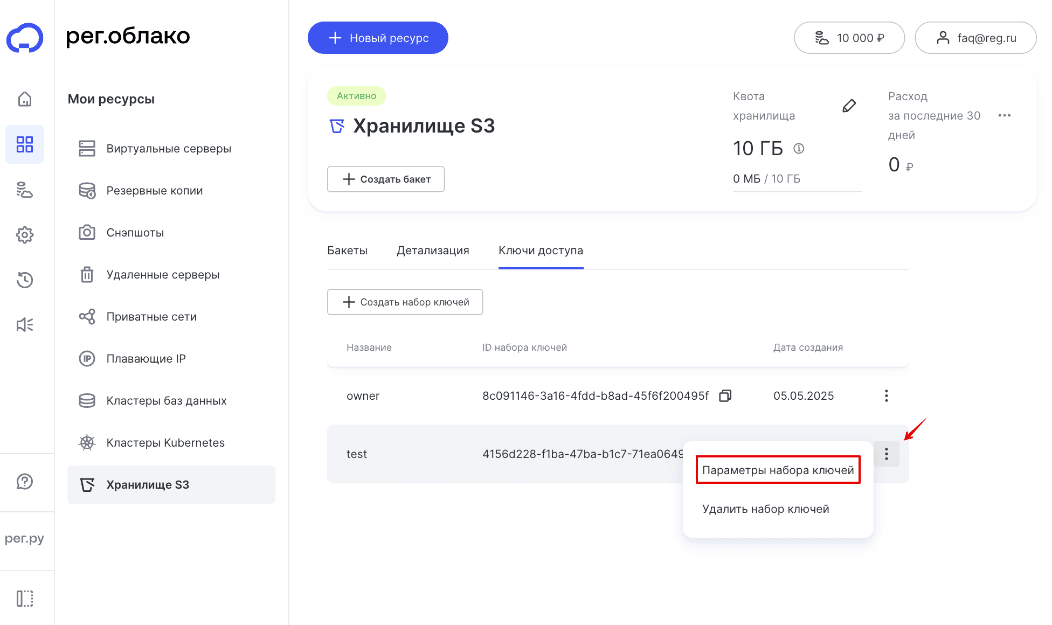
-
5
Скопируйте значения из строк S3 API Endpoint, Access key ID и Secret access key:
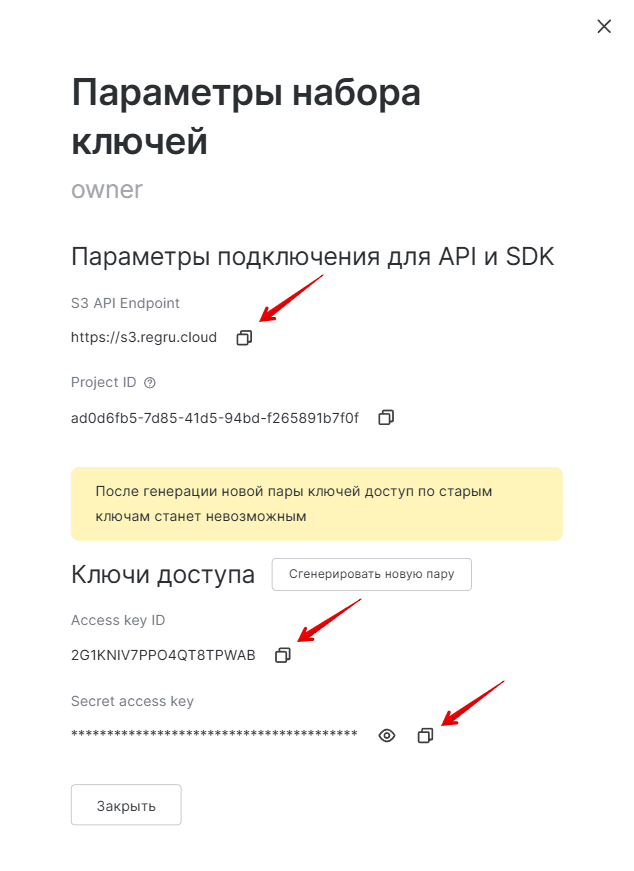
Теперь вы можете приступить к настройке конфигурации.
-
1
Откройте интерфейс командной строки на вашем ПК.
-
2
Выполните команду:
aws configure -
3
Поочередно укажите значения строк Access key и Secret access key из шага 4 инструкции выше.
-
4
Оставьте поле указание региона пустым. Затем нажмите Enter.
-
5
Откройте конфигурационный файл .aws/config. В качестве endpoint_url добавьте значение из строки S3 API Endpoint (шаг 4 инструкции выше). Затем сохраните изменения и закройте файл.
-
6
Проверьте, сохранены ли изменения. Для этого можно запросить список контейнеров:
aws s3 lsЕсли на экране отобразится список контейнеров, значит настройка выполнена корректно.
Готово, вы настроили доступ с аутентификацией.
Доступ без аутентификации
Этот способ доступен, если для бакета установлен публичный тип доступа. Чтобы получить доступ без аутентификации, можно использовать два варианта действий.
ACL
ACL (Access Control List) — это список контроля доступа к объектам в S3. Он определяет: какие пользователи могут получить доступ к определенному файлу, какие операции может выполнять пользователь с этим объектом.
Чтобы настроить список контроля доступа к объекту с помощью предопределенных ACL:
-
1
Откройте интерфейс командной строки на вашем ПК.
-
2
Выполните команду настройки. Например:
aws s3api put-object-acl --bucket bucket_name --key object_id --acl public-readГде:
- bucket_name — название контейнера,
- object_id — идентификатор объекта.
Полный список предопределенных ACL вы можете найти в официальной документации aws.
policy.json
policy.json — это конфигурационный файл, который регулирует настройки доступа к объектам S3. В качестве примера мы создадим файл, в котором открыт доступ для чтения всех объектов бакета. Другие варианты конфигурации вы можете найти в официальной документации.
Чтобы создать настройки доступа:
-
1
Откройте текстовый редактор на вашем ПК. В новый файл добавьте строки:
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": [ "arn:aws:s3:::bucket_name/*", "arn:aws:s3:::bucket_name" ] } }Вместо bucket_name укажите имя вашего контейнера. После этого сохраните файл под названием policy.json.
-
2
Откройте интерфейс командной строки на вашем ПК.
-
3
Выполните команду:
aws s3api put-bucket-policy --bucket bucket_name --policy С://Documents/policy.jsonГде:
- bucket_name — название контейнера,
- С://Documents/policy.json — путь к файлу policy.json.
После этого вы можете получить доступ на чтение объектов по специальной ссылке. Чтобы найти ее:
-
1
Авторизуйтесь в личном кабинете.
-
2
Откройте панель управления облаком.
-
3
Перейдите в раздел Мои ресурсы — Хранилище S3. Затем кликните по строке с именем нужного бакета:
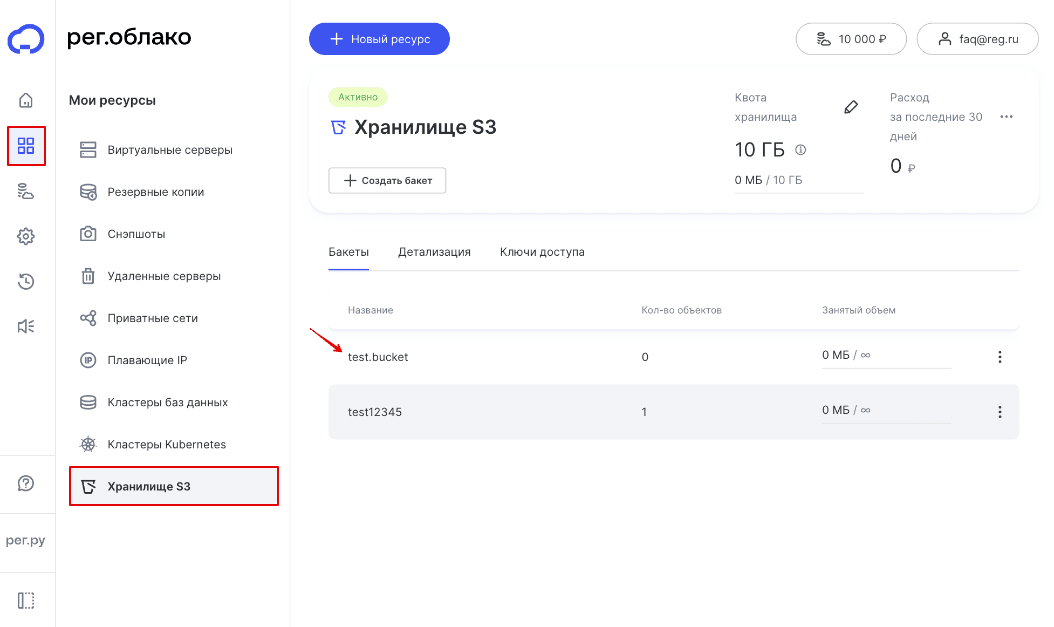
Как расшифровывается S3: Simple Storage Service
-
4
Выберите вкладку Подключение. Скопируйте значение из строки Path-style ссылка:
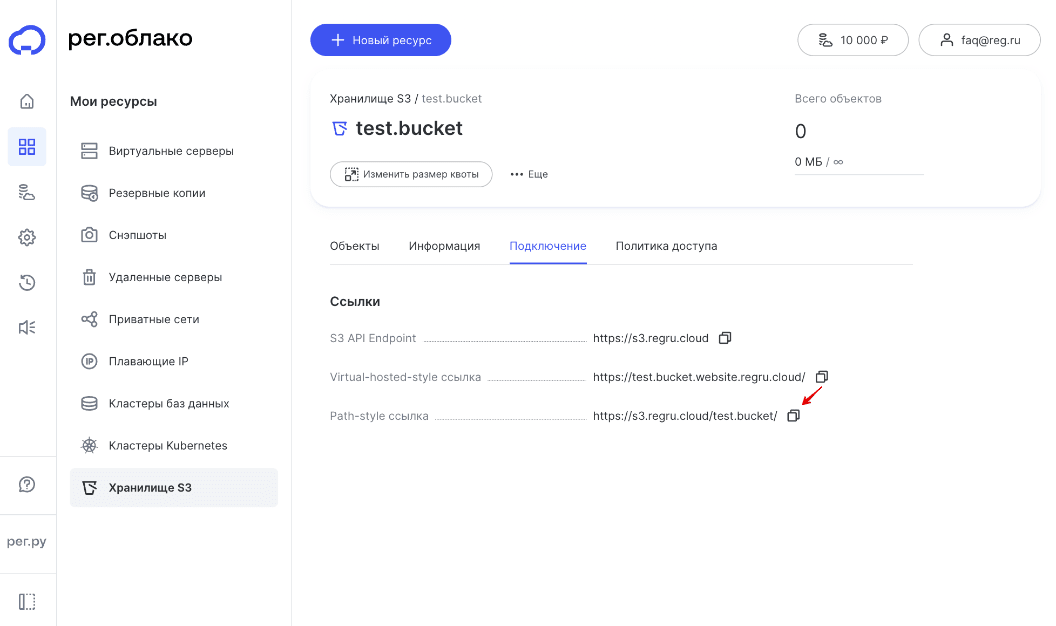
Если вам нужно получить конкретный объект, ссылка будет иметь следующий вид:
https://s3.regru.cloud/bucket_name/object_idГде:
- bucket_name — название контейнера,
- object_id — идентификатор объекта.
Готово, вы настроили доступ к объектам без аутентификации.
Доступ по предподписанным ссылкам
Этот способ доступа удобен тем, что вы можете указать время жизни ссылки. Чтобы сгенерировать ссылку:
-
1
Откройте интерфейс командной строки на вашем ПК.
-
2
Выполните команду:
aws s3 presign s3://bucket_name/object_idГде:
- bucket_name — название контейнера,
- object_id — идентификатор объекта.
Время жизни созданной ссылки по умолчанию составит 3600 секунд. Если вам нужно настроить собственное время жизни ссылки, выполните команду:
aws s3 presign s3://bucket_name/object_id --expires-in n-secondsГде:
- bucket_name — название контейнера,
- object_id — идентификатор объекта,
- n-seconds — время жизни в секундах.
После выполнения одной из команд на экране отобразится предподписанная ссылка.
Готово, вы настроили доступ по предподписанным ссылкам.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь 😊